SERVICE PHONE
13988889999SERVICE PHONE
13988889999发布时间:2026-01-10 18:59:51 点击量:
hashgame,hashgames,hash game casino,hash game sign up,hash game download/BETHASH GAME [PermaLink: 363050.com] is the largest official cryptocurrency game. Fair and just, 1 second commission return, providing: hashgame,hash game download,BTC, ETH,TRC20,TRX不知不觉中,2025年又走到了末尾。相比于略显平淡的2024年,今年的消费级显卡市场显然精彩很多,原因也很简单:到了换代的时候了——这边NVIDIA掏出了Blackwell,那边AMD就带来了RDNA 4,而年前刚刚推出锐炫B580的英特尔也继续丰富着Battlemage的产品线。同时,随着新一代硬件的推出,各家的软件——这里主要是指游戏增强技术,也得到了更新。另外,令人欣喜的是,随着AI热潮(以及相关管制)的持续,不少国产新面孔也端出了自己的GPU解决方案去竞争这一块空白地带。接下来,就让我们回到起点,看看这一年里的大小事。
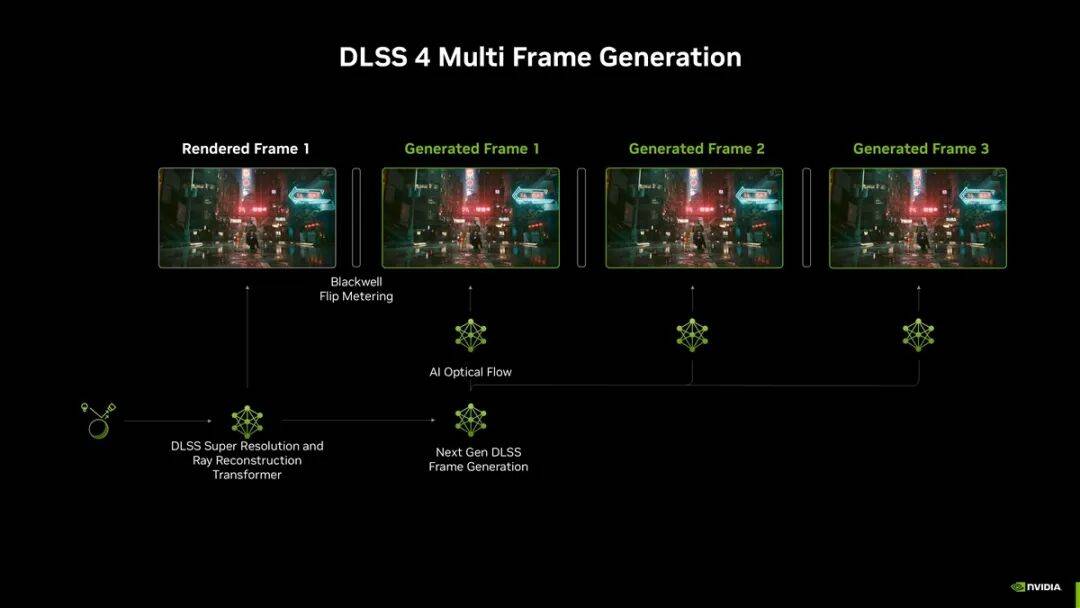
NVIDIA还带来了全新的DLSS 4技术,除了引人注目的多帧生成外,还有基于Transformer模型打造的超分辨率。多帧生成目前是RTX 50系独占,而Transformer模型超分辨率则支持所有RTX显卡,甚至包括RTX 20系,因为它们也有Tensor Core。
经过一系列的评测不难发现,RTX 5090 D继续捍卫了自己的王者地位,它与RTX 4090 D拉开了一段相当长的距离,仍能担当起最强游戏显卡之名。RTX 5080相比起RTX 4080有所进步,不过相比之下,Founders Edition的体积更值得表扬。

RTX 5070 Ti是我们觉得非常不错的一张显卡,它在多项测试中大幅领先RTX 4070 Ti,甚至达到了RTX 4080的水平,再加上DLSS 4的支持,玩4K游戏不是什么问题。价格上,RTX 5070 Ti比上一代略低,这显得它更有竞争力了。

至于RTX 5070,它对RTX 4070的平均游戏性能领先幅度达到了27%,不过和RTX 4070 SUPER比较的话呢可能就不算突出了。当然,DLSS 4带来的改变是立竿见影的,这个不可否认。我们的评价是适合那些跨代换卡,或者有AI需求的玩家选择。
AMD在CES 2025上只是简单说了说RDNA 4架构和FSR 4技术这些事情,没有很进一步地解说。因此我们只有等到3月,才能从RX 9070 XT和RX 9070两张显卡上了解全貌。

全新的RDNA 4架构引入了第三代光线追踪加速器,使得光线提升了两倍。第二代AI加速器不仅提升了FP16、INT8的算力,还引入了对FP8的支持。也得益于这个FP8支持,FSR 4才得以实现。

FSR 4基于机器学习驱动,相比FSR 3.1在图像质量上有着明显的提升。也因为需要FP8支持,所以它是Radeon RX 9000的独占功能,至少官方层面上是这样子。

回到显卡本身,RX 9070 XT和RX 9070都是基于Navi 48核心打造,只是前者是完整的64个CU,后者是56个。此外,RX 9070 XT的核心频率也更高。不过显存上两张显卡没什么区别,都是16GB GDDR6。
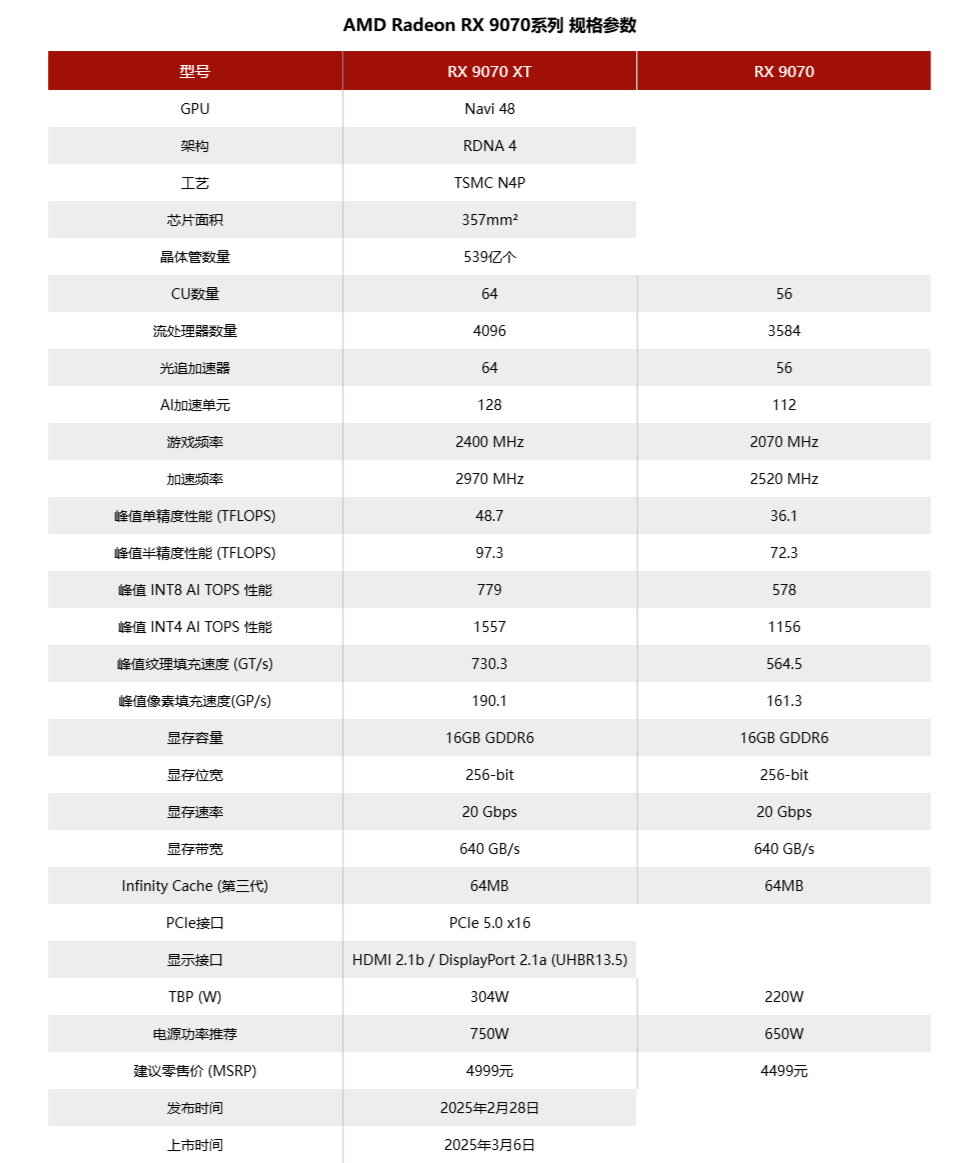
测试下来两张显卡的进步确实非常大,这不仅仅是和自己上一代比,还是跟GeForce RTX 50系相比得出的结论:RX 9070 XT的光栅性能比RTX 5070 Ti还要好,只是光追方面略逊一筹;RX 9070则实现了对RTX 5070的全面超越。更重要的是,两张卡都比对面的x070要便宜,性价比很足。
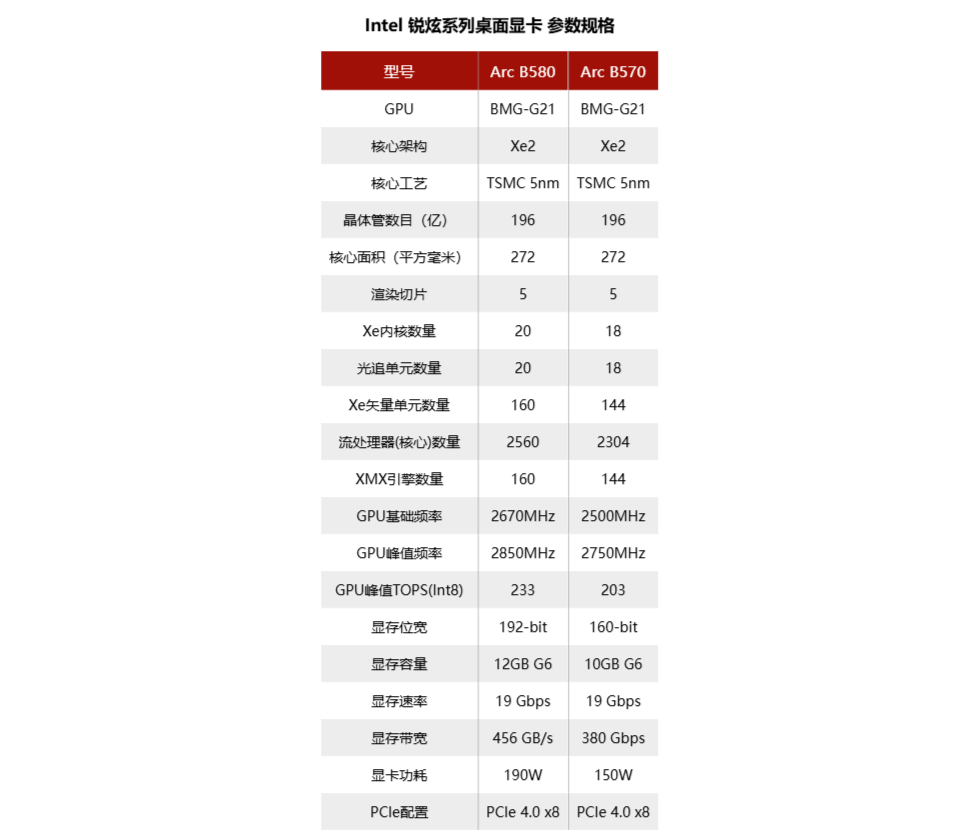
上面说到的显卡都是在CES 2025上发布的,其中最快发售的显卡RTX 5090 D也得等到1月24日,因此可能谁也想不到的是,锐炫B570才是2025年的最先发售的显卡,它在1月16日就推出了。

这张显卡和锐炫B580一样基于BMG-G21核心打造,不过比锐炫B580少了两组Xe核心。同时,锐炫B570的显卡功耗与频率也相应降低,显存也变成了10GB GDDR6。
RX 7650 GRE这一张版显卡应该是挺出人意料的,毕竟当时大家都在期盼着RDNA 4架构的到来,倒没想过AMD还能在RDNA 3上动一动,而且动的还是最小的那一颗芯片:Navi 33。

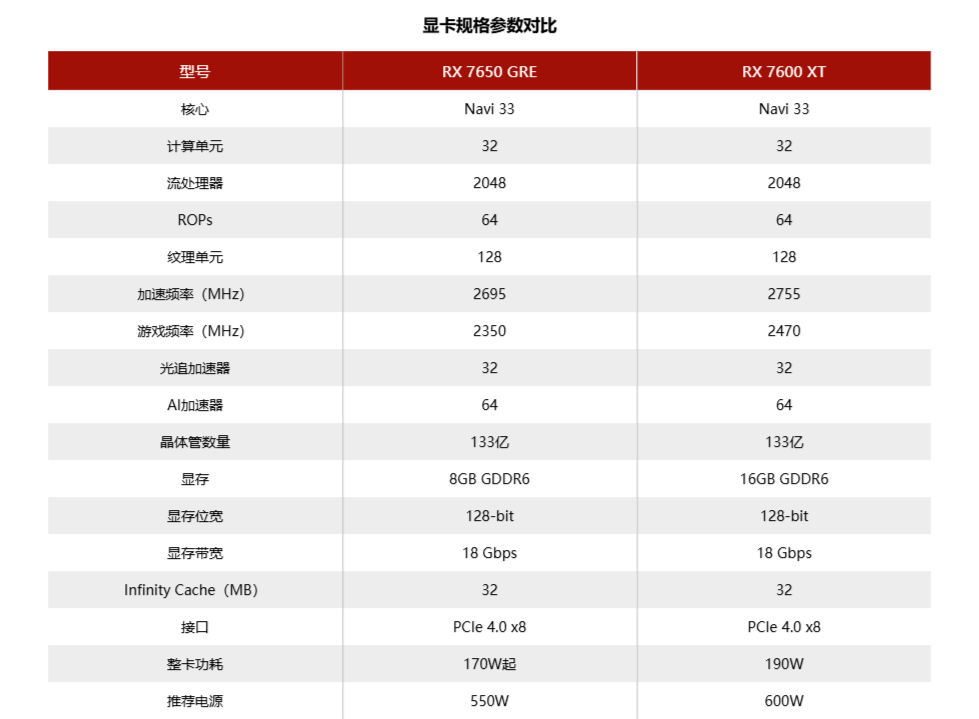
这张卡在性能上属于是和RTX 4060打得难解难分的类型,它在光栅化游戏上成绩更好,但是RDNA 3的光追性能明显落后。总的来说,这张显卡应该是一张接任RX 6750 GRE 10GB的入门级显卡,2049元的起步价证明了这点。
初创企业Bolt Graphics发布了一个全新的GPU设计,其名为Zeus架构。它用于高性能工作负载,涵盖渲染,高性能计算(HPC)和游戏。和我们熟知的一般显卡不一样,这款GPU的扩展性十分灵活。

Zeus GPU采用了Chiplet设计,每个完整的芯片由1、2或4个计算模块组成,而计算模块内部是基于RISC-V架构的自定义扩展设计,结合了矢量引擎与其他专用加速器。为了更好地满足高性能工作负载的需求,Zeus GPU具有大量片上缓存,片外缓存则采用LPDDR5X与DDR5结合的方式,其中DDR5支持可插拔设计。Bolt Graphics允许用户将PCIe卡中的显存增加到384GB,2U服务器中每个Zeus的内存可增加到2.25TB,一个机架的Zeus 2U服务器可配置高达180TB显存,是传统GPU的8倍。

另外,RTX PRO 6000 Blackwell还有一个主打高能耗的Max-Q版本。该显卡的整卡功耗为300W,仅为服务器和普通工作站版本的一半。其采用了经典的涡轮散热设计,双槽厚度。

微软表示,这次更新有望带来突破性的性能改进和令人惊叹的视觉保真度,将为世界各地的游戏玩家提供身临其境、逼真的游戏体验,实现又一个里程碑。另外还通过对PIX的更新,为开发人员带来了最新、最强大的DirectX工具。通过与行业领导者(包括AMD、英特尔、NVIDIA和高通)以及Remedy等游戏工作室合作,展示了这些进步如何重新定义Windows游戏中的沉浸感。
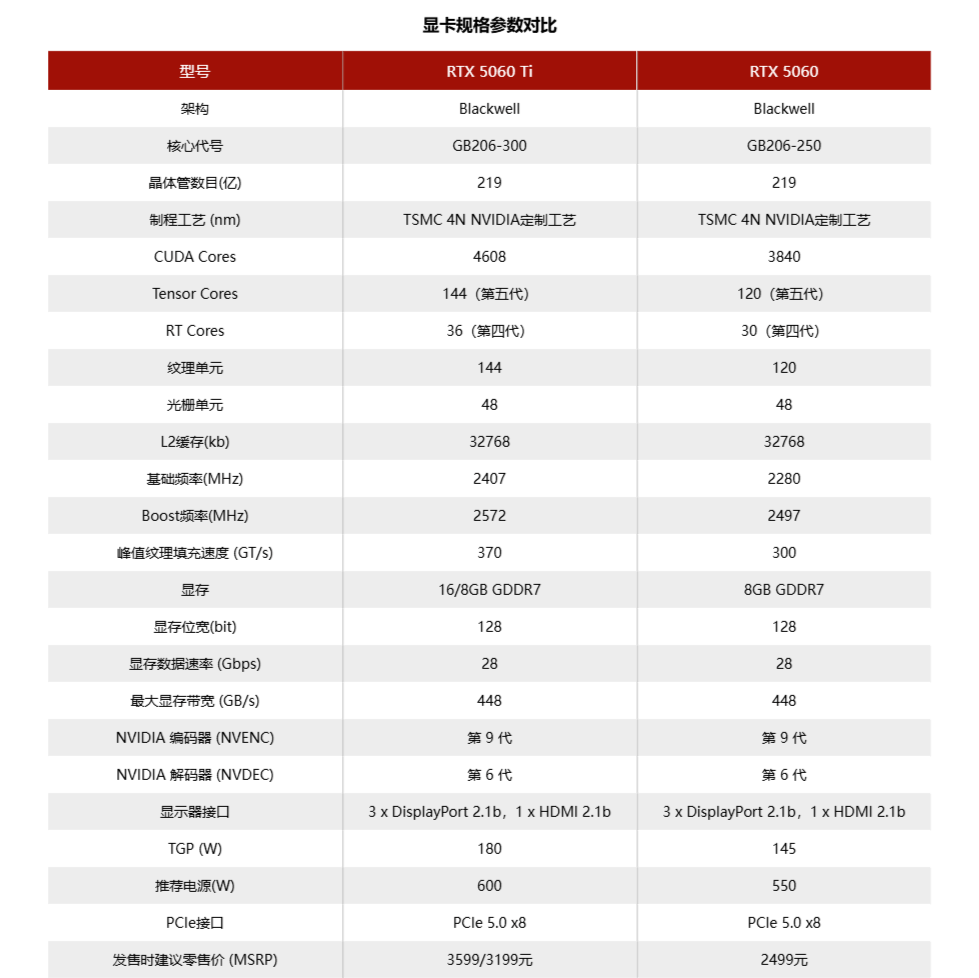
虽然RTX 5060 Ti的两种显存版本会在同日发售,但就我们当时收到的测试显卡数量来看,RTX 5060 Ti 16GB才是重点,这个倒是和RTX 4060 Ti的时候有明显的区别。另外一个就是RTX 5060 Ti并没有Founders Edition,这点比较可惜。

和RTX 4060 Ti 16GB相比,RTX 5060 Ti 16GB在游戏里的提升达到了18%。它在2K和1080P这两个分辨率中拥有着不错的表现。即便性能上没有接近RTX 4070,体验上还是相距不远的。至于RTX 5060 Ti 8GB这张显卡,没有8GB显存确实令它的游戏表现略逊于16GB版本。

然后是RTX 5060,这张显卡要等到5月20日才发售。这次RTX 5060相比于上一代最大的变化自然是那颗GB206-250核心,要知道RTX 4060用的是AD107-400。因此就数量而言,RTX 5060核心的整体规模比RTX 4060多出25%。这里还没算上架构、显存上的升级。而和采用更高一级核心的RTX 5060 Ti比较的线%。

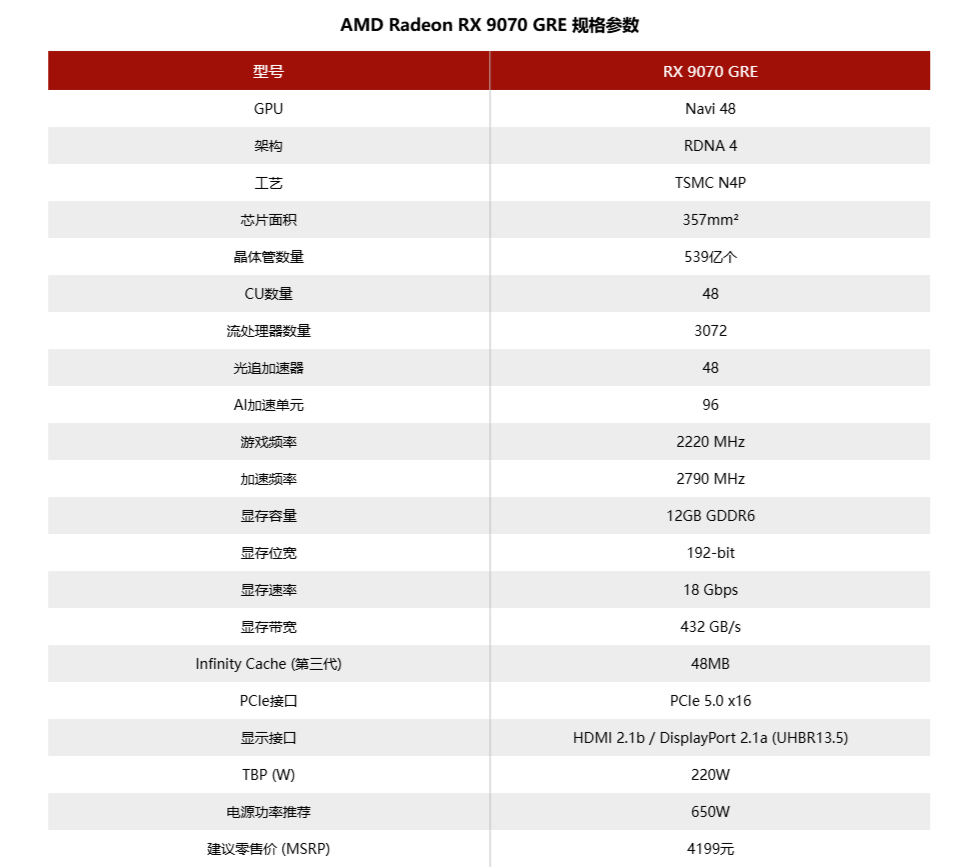
正当我们等待RX 9060系列的时候,AMD再出奇招,推出了RX 9070 GRE。这张显卡和早前推出的RX 9070相比,削减的地方还是挺多的,它的CU少了8个,Infinity Cache减至48MB。还有最重要的,显存是12GB GDDR6,位宽是192-bit,速度是18Gbps。

英特尔在Computex 2025上发布了ARC PRO B系列专业级显卡,采用最新的Xe2架构GPU,搭载英特尔XMX AI核心和先进的光线追踪单元,为创作者、开发者和工程师提供强大的性能支持。

首批的ARC PRO B系列专业级显卡有两款,当中ARC PRO B50是面向图像工作站的,而ARC PRO B60则面向推理工作站,它们用的GPU其实就是现在ARC B580上面的BMG-G21,但为了面对专业市场的大数据流量和高带宽需求,ARC PRO B系列用的是PCIe 5.0 x8接口,这是现在ARC B系列消费级显卡所没有的。


此外ARC PRO还支持多卡并行,Intel还发布了一款可配置的工作站级至强平台,代号Project Battlematrix,最多可支持八块英特尔锐炫Pro B60 24GB,也就是拥有高达192GB的显存,可运行高达1500亿参数的中等规模且精度高的AI模型。
RX 9060 XT基于Navi 44核心打造,从计算单元、光追加速器和Infinity Cache等组件的规格上可以看到,Navi 44正好是Navi 48的一半。而更小的核心换来的不仅有功耗的降低,还有频率的提升。显存的线两款。值得一提的是,RX 9060 XT全系列均是PCIe 5.0 x16,这比RX 7600时的PCIe 4.0 x8好很多。

和更高级的RX 9070测试时一样,RX 9060 XT 16GB拥有叫板RTX 5060 Ti 16GB的能力,在光栅化游戏和一般的光线追踪游戏中都能和RTX 5060 Ti 16GB打得有来有回。而RX 9060 XT 8GB虽然有着相同的核心,但Radeon显卡受显存的影响还是比较明显的,因此这张显卡在高分辨率、高画面预设和光线追踪等显存告急的情况下,帧率会比RTX 5060 Ti 8GB来得更低,但对付RTX 5060仍然不是什么问题。当然,“爆显存”就是另一件事了,我们在评测里面也讨论了这个话题。
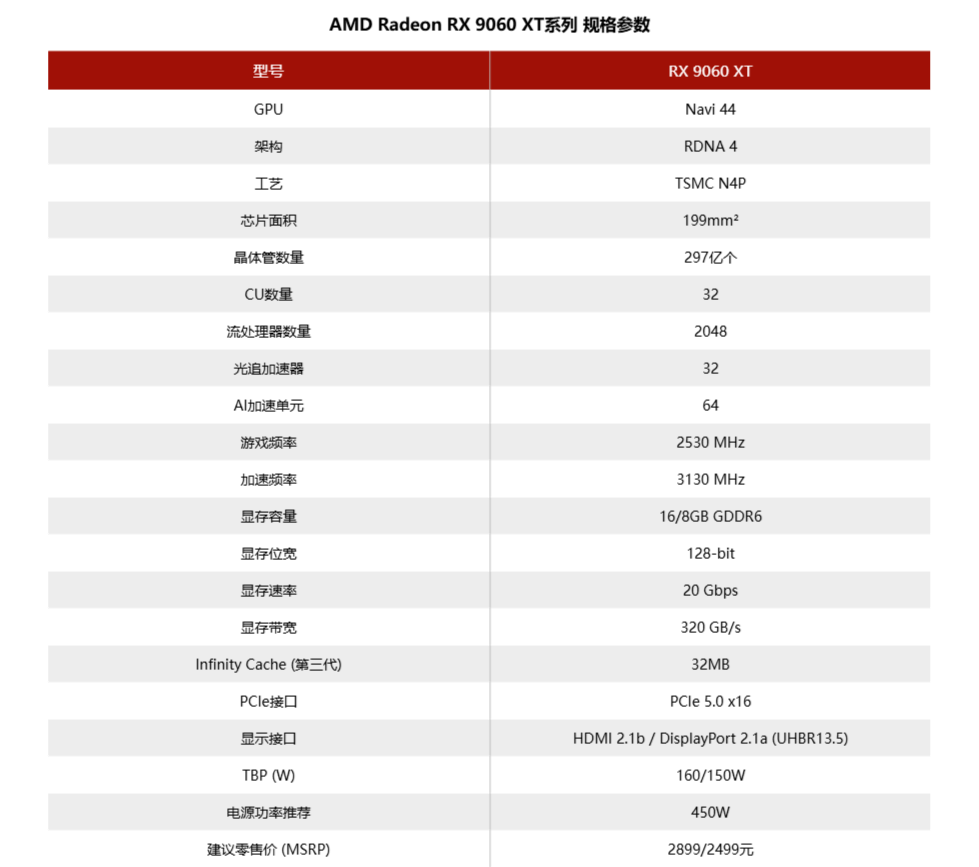
以售价来说,两张RX 9060 XT的起售价都处在一个比较巧妙的区间。RX 9060 XT 16GB的MSRP为2899元,比RTX 5060 Ti 8GB(3199元)还要低,可以说是新一代16GB显存显卡里面最为实惠的。而RX 9060 XT的价格和RTX 5060一样都是2499元,也是一个具有竞争力的价格。
AMD在6月13日正式发布CDNA 4架构及Instinct MI350系列GPU,新架构在计算密度、能效比和内存带宽方面相比上代产品有显著的优化,同时支持灵活的硬件分区和开放的生态系统,为生成式AI和大语言模型训练与推理带来突破性的性能提升。
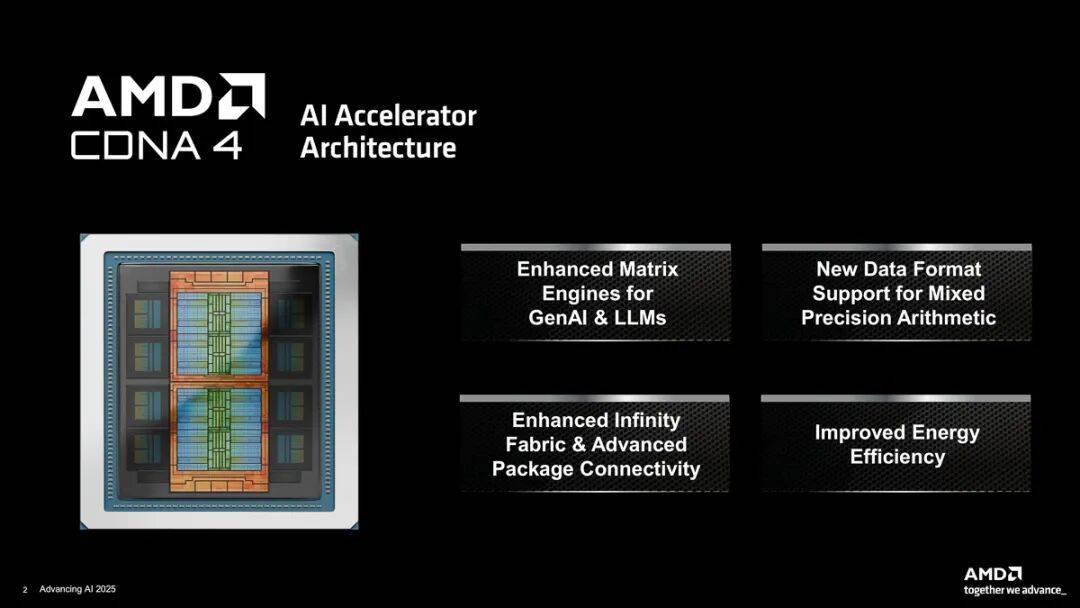
Instinct MI350系列GPU基于迭代升级后的芯片堆叠封装工艺打造,采用N3P工艺的加速器复合核心(XCD)通过COWOS-S封装技术堆叠在采用N6工艺的I/O核心(IOD) 之上,IOD-IOD互连以及HBM3E显存的集成则给予2.5D架构打造。8堆栈的HBM3E显存为Instinct MI350系列GPU带来了288GB的高容量与8TB/s的高读取带宽。数据格式上则新增了FP6与FP4的支持。

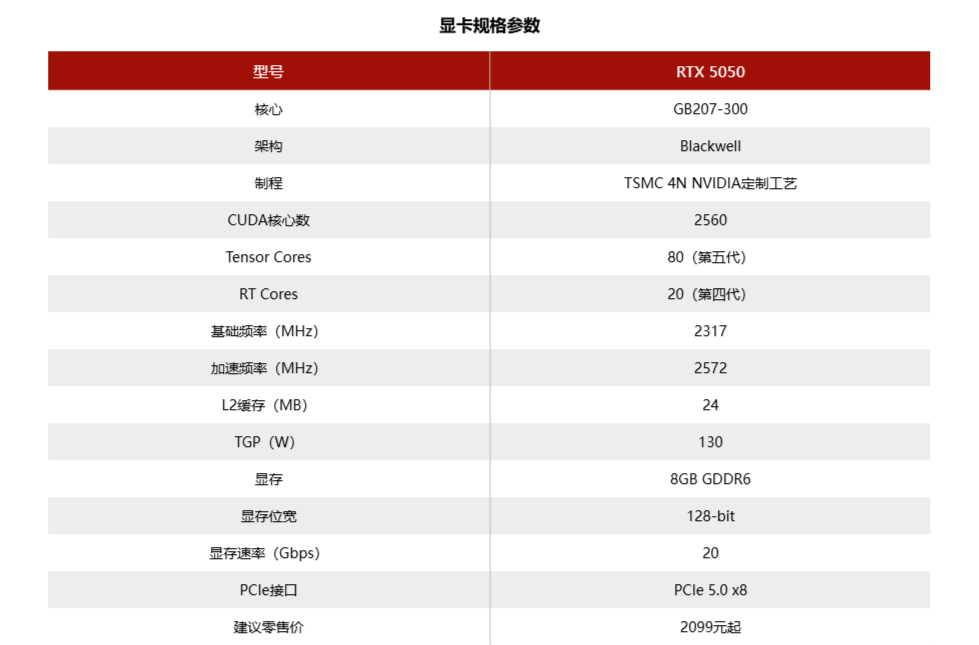
性能方面,这张显卡相当接近上一代的RTX 4060,两者原生分辨率游戏的帧率差距在10%以内。而且更重要的是,RTX 5050也是拥有全部Blackwell特性的一张卡,借助DLSS 4,它能在1080P的光追游戏中展现出一个高达三位数的帧率,这可比RTX 4060还要强。

不过价格上,RTX 5050突破了2000元大关,以2099元起售。至于是不是该加400元换到比它强20%的RTX 5060,就全看各位心意了。但如果你是从RTX 3050甚至更老显卡升上来的线给人的满足感还是挺大的。
砺算科技于7月26日发布了首款GPU芯片“7G100”系列和首款显卡产品Lisuan eXtreme系列。砺算7G100系列是一款全自研高性能图形GPU,基于自研TrueGPU天图架构,并自研指令集、自研软件栈,从指令集到计算核心完全由自主设计。砺算科技表示,新产品以效率、平衡、拓展为重,多重性能优势达到国际主流、国内领先水平。此外,砺算7G100系列支持NRSS动态优化渲染画质,可实现对英伟达DLSS技术和AMD FSR技术的对标。

就算RTX 5090 D是一张版显卡,随着大环境的变化仍然是难逃一ban。这使得NVIDIA不得不掏出新产品来填补上旗舰级显卡这个空位。早在5月RTX 5090 D被禁的时候,就有RTX 5090 DD这一个名字传出——还好,NVIDIA最后并没有选择这么一个以中文读音看来有点尴尬的名字,而是用RTX 5090 D v2称呼这么一张新显卡。

RTX 5090 D v2是在8月中旬推出的。它采用GB202-250核心打造,但它的规格和RTX 5090 D的GB202-250真没啥区别,无论是CUDA数量还是频率都一样。但大的在显存这边:RTX 5090 D v2从32GB GDDR7一下子降到了24GB GDDR7,直接没了一份RTX 5060的量,位宽和带宽自然也同步降低了。当然,24GB仍然是个很大的数字,毕竟也没多少显卡有这个规格,更别提GDDR7了。
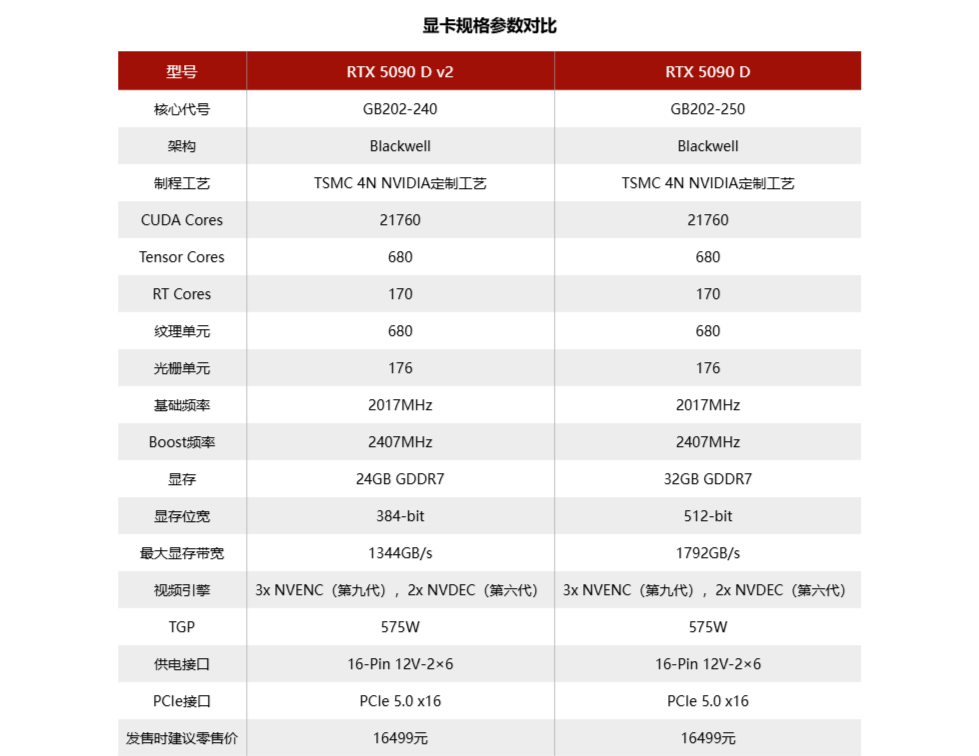
测试的结果是RTX 5090 D v2在游戏性能上维持了GeForce RTX 5090 D的水平,但在AI和生产力应用领域这块,RTX 5090 D v2确实要比GeForce RTX 5090 D更低,幅度大概是10%。总的来说,消失的8GB显存对于游戏似乎没什么影响,大概是24GB对于现在的4K游戏来说已经足够了。
虽然RX 9000系的布局是差不多,但AMD还是在9月推出了一款RDNA 3显卡Radeon RX 7700。它用了Navi 32芯片,拥有40个CU,即2560个流处理器,并搭配16GB的GDDR6显存。供电方面,它配有双8Pin供电接口,整卡功耗为263W,AMD推荐使用额定功率700W的电源。

虽然RX 7700比起RX 7700 XT的CU数量更少了,但是显存位宽和容量都更大了,而且速率也更高了,达到了Radeon RX 7800 XT的水平,这显然更符合目前游戏对显存容量的要求越来越高的趋势。
2025年9月22日,芯动科技在珠海正式发布了“风华3号”GPU。该GPU采用全国产底层设计,同时拥有AI智算算力和8K重度渲染算力,兼容DirectX 12、Vulkan 1.2、OpenGL 4.6等图形接口,并适配统信、Windows、Android、麒麟等操作系统。

“风华3号”GPU还在行业内率先实现国产开源RISC-V CPU与CUDA兼容GPU的深度融合,也是全球首个实现了DICOM高精度灰阶医疗显示功能的GPU产品。同时,它不仅,支持单卡多用户32B/72B轻量化部署,也支持单机八卡满血版 671B DeepSeek/ Qwen235B,同时还支持单节点 64 卡/ 128卡/ 256卡超节点配置,提供了充足的AI性能。
新款RTX PRO 5000 72GB Blackwell换用了24Gb (3GB) 的GDDR7模块,共24个分列在PCB两侧,将显存容量提高至72GB,增大了50%。由于显存位宽和速率也相同,对应的显存带宽仍然为1344GB/s。同时,NVIDIA RTX PRO 5000 72GB Blackwell仍然保持着双槽厚度,采用了经典的涡轮散热设计,整卡功耗也同样是300W,并没有因显存容量变大而增加,通过单个12V-2×6接口供电。对于数据科学、人工智能(AI)、高性能计算(HPC)和专业视频编辑等领域的专业人士来说,显然新产品更具有吸引力。


存储系统方面,这两张卡都拥有64MB的Infinity Cache,并搭配32GB的GDDR6显存,位宽为256-bit,速率为20Gbps,带宽为640GB/s。均配备12V-2×6供电接口。值得一提的是,和R9700的涡轮散热不同,两张卡都是采用被动散热设计。
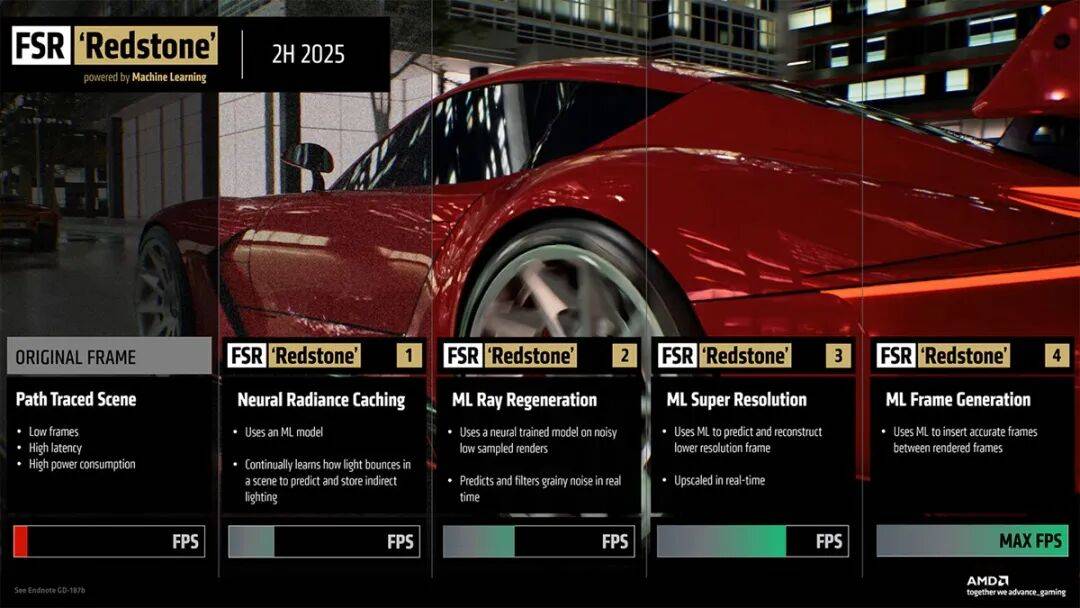
其中,FSR光线再生、FSR优化升级、和FSR帧生成是即时可用的,而FSR辐射缓存要等到2026年才释出。AMD表示,目前有超过170款游戏支持FSR Redstone功,未来这个数目还会持续增长。
在2025年快结束的时候,摩尔线程召开了首届MUSA开发者大会。在大会上,摩尔线程公布了一系列重大突破:首先是全功能GPU架构“花港”,该架构基于新一代指令集打造,算力密度提升50%,能效大幅优化,且支持的AI运算格式更多。在图形方面,“花港”内置AI生成式渲染架构,增强了硬件光线追踪加速引擎,并完整支持DirectX 12 Ultimate。

基于“花港”架构,摩尔线程公布了未来将发布的两款芯片:第一款是专注AI训推一体与超大规模智能计算的“华山”。它集成了新一代异步编程与全精度张量计算单元,支持从FP4至FP64的全精度计算,为万卡级智算集群提供了稳定高效的算力支撑。第二款则是专攻图形的“庐山”,它的AI计算性能提升64倍,几何处理性能提升16倍,光线倍,并显著增强纹理填充、原子访存能力及显存容量。


具体的硬件方面,摩尔线程发布了夸娥万卡智算集群。该集群具备全精度、全功能通用计算能力,可在万卡规模下实现高效稳定的AI训练与推理,其核心突破包括:浮点运算能力达到10Exa-Flops,训练算力利用率(MFU)在Dense大模型上达60%,MOE大模型上达40%,有效训练时间占比超过90%,训练线%,与国际主流生态高度兼容,并在多项指标上具备显著能效优势。

针对个人用户侧,摩尔线程带来了搭载自研“长江”智能SoC的MTT AIBOOK,它提供高达50TOPS的端侧AI算力,首次实现从芯片、驱动到开发环境的全栈整合。还有MTT AICube这款迷你型计算设备,它也是基于“长江”SoC打造的。

2025确实是足够精彩的一年。从数量上来说,今年的新显卡是足够多的,NVIDIA这边从RTX 5090一直出到了RTX 5050,从旗舰到入门都一应俱全,线时还热闹;AMD的显卡虽然只基于两颗RDNA 4核心打造,但该有的都有,准确覆盖了主流的玩家群体;英特尔则是在Xe2架构的基础上稳步扩展——对了,国产GPU厂商们的涌现也是值得提及的一点。
从质量,或者是功能上来说呢,今年的显卡们表现得也是足够出色。Blackwell引入了一系列面向未来的渲染技术,DLSS 4对游戏的画面和帧率都是一个大提升;RDNA 4在光线追踪性能上紧追对手,基于机器学习的FSR 4也是一改FSR 3时期平平无奇的表现,在画面清晰度上有着显著的升级。
你也许注意到副标题的后半段略带一点“灰色”,这其实是出于某种担忧:随着AI热潮的持续,消费级硬件受到的影响并不亚于几年前的加密货币时期——谁能想到内存颗粒的售价竟然如此高企?对于意欲升级硬件的玩家来说,这绝对不是一个好消息。
不过,我们总是要向前看的。CES 2026上,NVIDIA推出了DLSS 4.5技术,更早前,AMD也带来了FSR Redstone更新,如果没法在硬件规格和显存容量上更进一步,依靠这些增强技术和持续更新的超分辨率AI模型来保证游戏体验,也是一种度过难关的好方法。返回搜狐,查看更多


